Svd Nedir
SVD ile Kümeleme, Benzerlik
Eşsiz Değer Ayrıştırma (Singular Value Decomposition -SVD-) ile bir veri madenciliği örneği göreceğiz. [6]'da SVD'nin matematiğini işledik. SVD bir matris $A$ üzerinde ayrıştırma yapar, ve $A$ herhangi boyutta, türde bir matris olabilir.
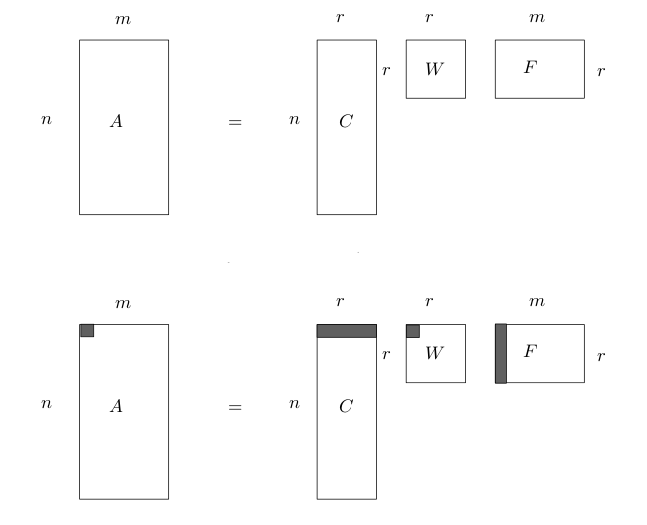
Ayrıştırma $m \times n$ boyutlu matrisi $A=CWF$ olarak ayrıştırır, burada $C$, ana matris ile aynı miktarda satıra sahiptir, $F$ aynı miktarda kolona sahiptir. Ayrıştırma sonrası $A$'nin kertesi (rank) $r$ ortaya çıkar, eğer tüm $A$ kolonları birbirinden bağımsız ise, o zaman $r=m$ olacaktır, ama kolonların bazıları mesela aynı ölçümü değişik katlarda tekrarlıyor ise, o zaman matriste eşsizlik vardır, ve bu durumda $r < m$ olur, ve ortadaki $W$ matrisi $r \times r$ olduğu için beklenenden daha ufak boyutlarda olabilir.
Ayrıca SVD, $W$ çaprazındaki özdeğerleri büyüklük sırasına göre dizer, ve her özdeğere tekabül eden özvektörler de ona göre sıraya dizilmiş olacaktır, ve SVD tamamlanınca mesela "en büyük 10" özdeğere ait olan $CWF$ değerlerini alıp, diğerlerini atmayı da seçebiliriz, yani kerte üzerinden yapılan "eleme" üstüne bir eleme de kendimiz yapabiliriz. Bu elemeyi yapabilmemizin mantığı şöyle; küçük özdeğerlerin çarptığı özvektörlerin nihai toplama daha az etki ettiği söylenebilir, ve bu "gürültüyü" elemek sonucu değiştirmeyecektir. Ayrıca bu elemeyi yaparak bir tür boyut azaltma (dimensionality reduction) işlemini de aynı zamanda başarmış oluruz.
Ayrıştırmanın Anlamları
Bir ayrıştırmayı değişik şekillerde görmek mümkündür. Bunlardan önemli birisi çizit bakış açısıdır (graph interpretation). Çizit bilindiği gibi düğümler ve onlar arasındaki ayrıtlardan (edges) oluşur. Bir çizit matris formunda temsil edilebilir, satır / kolon kesişimi iki düğüm arasındaki ayrıtın ağırlığını, ya da varlığını (1 ve 0 üzerinden) temsil edecektir. Bu durumda SVD sonucunda elde edilen $CWF$, bize iki düğüm arası geçişli (bipartite) çiziti üç düğüm arası geçişli (tripartite) çizite çevrilmiş halde geri verir. Ve bu yeni çizitde en fazla $r$ tane geçiş noktaları (waystations) oluşmuştur, üstte bahsettiğimiz eleme ile geçişler daha da azaltılabilir.
Şimdi, bu geçiş noktalarına olan $C$'nin "bağlanma şekli", "bağlanma kuvveti", ek kümeleme basamağı tarafından kullanılabilir. Bu "azaltılmış" geçişin üzerindeki her işlem / ona yapılan her referans kümeleme için bir ipucudur. Bunu görmek için örnek zaman serilerinin SVD sonrası elde edilen $C$ (örnekte ) matrisinin ilk iki kolonunu bile grafiklemek yeterlidir.
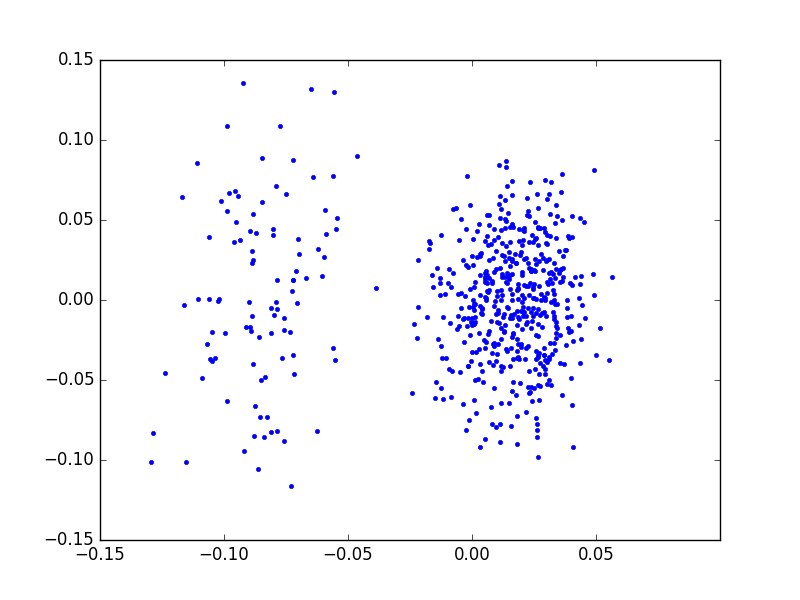
Görüldüğü gibi net bir şekilde iki tane küme ortaya çıktı. Bu kümeler yazının başındaki iki ayrı zaman serisi öbeklerine tekabül ediyorlar.
O zaman serilerini ayırtetmek için ne yaparız? Üstteki veriler üzerinde kmeans işletebilirdik, ya da kabaca bakıyoruz, dikey olarak -0.025 seviyesinde bir çizgi ayıraç olarak görülebilir. Numpy filtreleme tekniği
bize ana veri üzerinde uygulanabilecek ve değerleri verir, bunları alarak ana veriye filtrele olarak uygularız,
ve mesela birinci kümeye ait zaman serilerini bulabiliriz.
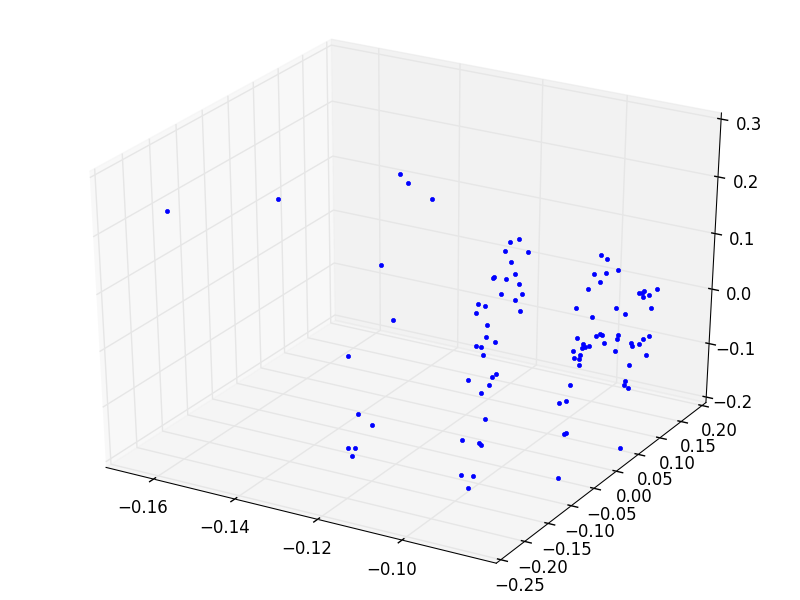
Kontrol etmek için ilk 3 kolonun değerlerini üç boyutta grafikleyelim.
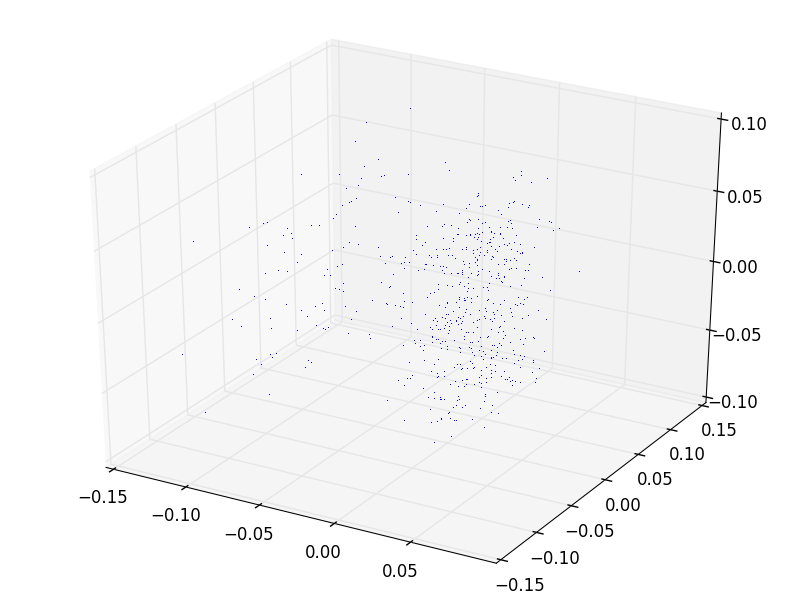
Yine iki tane küme olduğunu görüyoruz.
Kelime Vektorleri [5]
Diyelim ki elimizde üç tane cümle var. Bu cümlelere dayanarak bir kelimenin vektörsel temsilini bulmak istiyoruz.
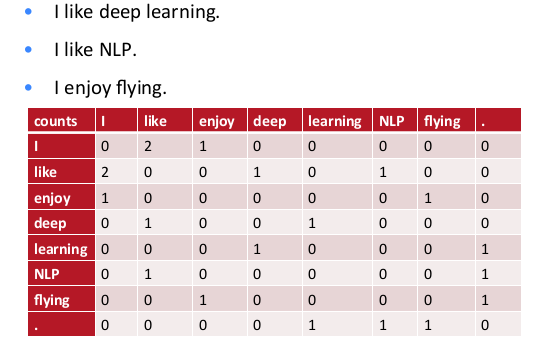
Matris içindeki sayılar her kelimenin bir diğeri ile beraber kaç kere aynı cümlede olduğuna (cooccurence) göre oluşturuldu. Mesela "I" ile "like" kelimesi beraber 2 kere çıkmış, bu matriste 1,2 ve 2,1 kordinatlarında görülüyor. O zaman bu matrise bir kelimenin satırsal ya da kolonsal temsiline bakarak o kelimenin vektörsel halini bulabiliriz. Mesela "enjoy" icin bu $\left[\begin{array}{cccccccc} 1&0&0&0&0&1&0 \end{array}\right]$.
Fakat gerçek uygulamalarda bu şekilde bir temsil performans ve depolama açısından bedeli olabilir; eğer eldeki kelime sayısı 1 milyon ise bu matris 1 milyon x 1 milyon öğeye ihtiyaç duyar.
Çözüm: boyut azaltmak. SVD bu iş için biçilmiş kaftan.
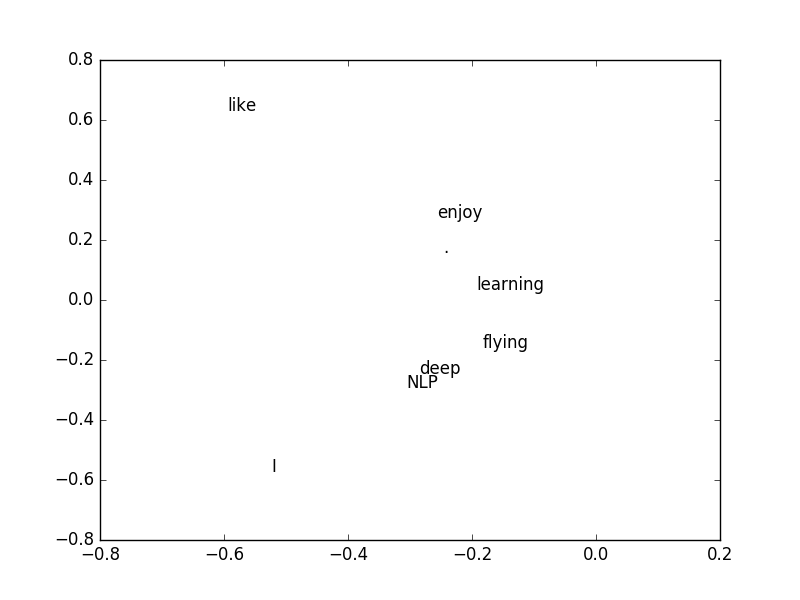
$U$'nun ilk iki kolonunu grafikledik çünkü en büyük iki eşsiz değere tekabül eden kolonlar bunlar, yani en "önemli" değerler orada.
En önemli kolonları bulduk, o zaman diyebiliriz ki bu iki kolon üzerinden bir kelimenin vektörsel temsilini de bulmuş olduk. Bu temsil eskisine göre daha küçük, ve özetleme açısından daha kuvvetli. Artık kelimelerin birbirine yakınlığı, benzerliği gibi hesaplar bu vektör üzerinden yapılabilir.
Üstteki grafik yakınlık açısından bazı anlamsal yapıyı göstermeye başladı bile: mesela "like" ve "enjoy" birbirine yakın, bu mantıklı çünkü ikisi de birinin yaptığı şeyler. Diğer yandan "learning" kelimesine en yakın "flying" bu da mantıklı, her iki kelime de cümle sonlarında ortaya çıkıyorlar ve hedef kelimeler.
Gerçek uygulamalar için bazı taklalar:
İngilizce'nin yapısı sebebiyle sürekli görülen ama çok anlam katmayan bazı kelimeler var, mesela "the", "he", "has" gibi. Bu kelimeler direk sayılırsa bu sayı çok yüksek. Çözüm, belli bir sayı üstünü saymamak, ya da onları tamamen devreden çıkartmak.
Word2Vec
Yapay Sinir Ağları (YSA) literatüründe duyulan word2vec aslında üstteki vektörsel temsilin başka bir yoldan öğrenilmesinden ibaret. YSA yaklaşımı ile beraber olma sayısı hesaplanmadan vektörsel temsil direk öğreniliyor, bunun için her kelime için o kelime yakınındaki (bir pencere içindeki) diğer kelimeler tahmin edilmeye uğraşılıyor, daha doğrusu hedef fonksiyon budur, ve eğitim verisine bakılarak bu tahmindeki başarı geriye yayılım (backpropagation -backprop-) ile düzeltilerek arttırılıyor.
Word2Vec'in insanı şaşırtabilen bazı ilginç özellikleri var: mesela çok büyük veriler üzerinden vektörler hesaplandıktan sonra mesela kral vektörünü alıp ondan erkek vektörünü çıkartıyorsunuz, ve kadın vektörünü toplayorsunuz ve kraliçe vektörünü elde ediyorsunuz (ona yakın bir vektörü en azından). İlginç değil mi? Bu keşif pek çok araştırmacıya "vay canına" dedirtirdi, tabii ki bunun istatistiki sebepleri var, bu konuya bakanlar da oldu, detaylar için [5, 18:50].
Örnek
Şimdi biraz daha değişik bir probleme bakalım, bu sefer bir grup kelimeyi birbirlerine benzerlikleri (ya da uzaklığı) üzerinden kümelemeye uğraşacağız.
Benzerlik, Levenhstein mesafesi adlı ölçüt [2] üzerinden olacak. Matrisimiz her kelimenin her diğer kelime ile arasındaki uzaklığı veren bir matris olmalı, eğer 100 kelime var ise, bu matris 100 x 100 boyutlarında olacak. SVD sonrası elde edilen üzerinde kmeans işleteceğiz, ve kümeleri bulacağız. Ayrıca her küme için bir "temsilci" seçebilmek için kmeans'in bize verdiği küme ortası kordinatının en yakın olduğu kelimeyi çekip çıkartacağız, ve onu temsilci olarak alacağız.
Kelime mesafesi olarak
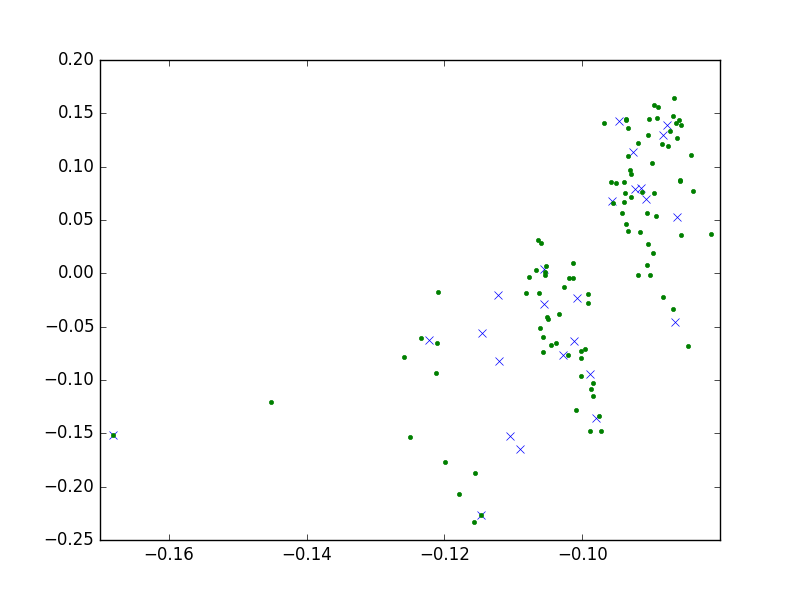
Bu tekniğin uygulanabileceği daha pek çok alan var. Mesela her dokümanın içindeki belli kelimelerin sayıları kolonlarda (her kolon özel bir kelimeye tekabül edecek şekilde), ve dökümanların kendisi satırlarda olacak şekilde bir matrisimiz olsaydı, SVD bu matris üzerinde de bir kümeleme için kullanılabilirdi. Bu örnekte "kaç tane kelime olduğu" gibi bir ölçüt vardır (daha önce kelimelerin birbirine uzaklığını kullandık), ama teknik yine de ise yarar.
Kaynaklar
Not: kullanımının tarifi için [4].
[1] Alcock, Synthetic Control Chart Time Series, kdd.ics.uci.edu/databases/synthetic_control/synthetic_control.data.html
[2] Bayramlı, Kelime Benzerligi - Levenshtein Mesafesi, https://burakbayramli.github.io/dersblog/sk/2012/07/kelime-benzerligi-levenshtein-mesafesi.html
[3] Skillicorn, D., Understanding Complex Datasets Data Mining with Matrix Decompositions
[4] Bayramlı, Dongu Yazmamak, Fonksiyonel Diller, Python, https://burakbayramli.github.io/dersblog/sk/2012/07/dongu-yazmamak-fonksiyonel-diller-python.html
[5] Socher, {\em CS224d, Deep Learning for Natural Language Processing, Lecture 2}, https://www.youtube.com/watch?v=T8tQZChniMk
[6] Bayramlı, Lineer Cebir, Ders 29
Yukarı
Yazan : Şadi Evren ŞEKER
Lineer Cebir (Linear Algebra) konusunda kullanılan ve reel veya kompleks matrisler üzerinde ayrıştırmaya yarayan önemli bir konudur.
Basitçe bir matrisi 3 parçaya ayırarak tutar ve bu üç parçayı kullanarak aynı matrisin yeniden elde edilmesini sağlar.
M = UΣV
U, vahid masfuf (üniter matris, unitary matrix) olmaktadır
V matrisi, M matrisinin birimdik (orthonormal) özelliklerini tutan matristir.
Σ matrisi ise bir köşegen matrisi olup (diagonal matrix) tekil değerleri (singular values) tutmaktadır.
Örnek (Selmirsel’in talebi üzerine ekliyorum)
Örneğin M matrisi olarak aşağıdaki matris verilmiş olsun.
M =
| 1.0000 | 2.0000 | 3.0000 |
| 4.0000 | 5.0000 | 6.0000 |
| 7.0000 | 8.0000 | 9.0000 |
Yukarıdaki bu matrisi, M = UΣV şeklinde çarpanlarına ayıracak ve buradan SVD değeri olan Σ matrisini bulacağız.
U =
| -0.2148 | 0.8872 | 0.4082 |
| -0.5206 | 0.2496 | -0.8165 |
| -0.8263 | -0.3879 | 0.4082 |
Σ =
| 16.8481 | 0.0000 | 0.0000 |
| 0.0000 | 1.0684 | 0.0000 |
| 0.0000 | 0.0000 | 0.0000 |
V =
| -0.4797 | -0.7767 | -0.4082 |
| -0.5724 | -0.0757 | 0.8165 |
| -0.6651 | 0.6253 | -0.4082 |
Yukarıda bulduğumuz bu 3 matrisi çarparsak M matrisi aşağıdaki şekilde , ilk beklediğimiz matris olarak geri bulunur:
U* Σ *VT =
| 1.0000 | 2.0000 | 3.0000 |
| 4.0000 | 5.0000 | 6.0000 |
| 7.0000 | 8.0000 | 9.0000 |
Kodlama
Yukarıda verilen bu matrislerin bulunmasını algoritmik olarak ele alacak olursak, program yazılacak kadar basit bir halde düşünebilmemiz gerekir. SVD hesaplanırken aslında bulunan değer basitçe
M = UΣV değeridir . Bu değeri aşağıdaki şekilde parçalara ayırabiliriz:
M[i][j] şeklindeki iki boyutlu matri için :
= Σi < k U[i][k] * S[k][k] * V[j][k] // M = UΣV ayrımındaki 3 ayrı matris
Yukarıdaki bu eşitlikte S matrisini karekökünün karesi şeklinde yazabiliriz:
S[k][k] = sqrt(S[k][k]) * sqrt(S[k][k]) // bir matrisin karekökünün karesi kendisi olduğuna göre
= Σi < k U[i][k] * sqrt(S[k][k]) * sqrt(S[k][k]) * V[j][k]
Çarpma işlemlerinin öncelikleri eşit olduğu için sondaki ve baştaki çarpmalara öncelik verebiliriz:
= Σi < k (U[i][k] * sqrt(S[k][k])) * (sqrt(S[k][k]) * V[j][k])
S matrisimizin köşegensel (diagonal) bir matris olduğunu yani sadece köşegenindeki değerlerin bulunduğunu bunun dışındaki değerlerin 0 olduğunu hatırlarsak, çarpım işlemini aşağıdaki şekilde basitleştirebiliriz.
= (U[i] * sqrt(Sdiag)T) * (V[j] * sqrt(Sdiag)T)T
Yukarıdaki denklemden faydalanarak tekil değer ayrışımını veren elemanlar aşağıdaki şekilde hesaplanabilir:
U[i] * sqrt(Sdiag)T
= { U[i][0] * sqrt(S[0][0]),
U[i][1] * sqrt(S[1][1]),
…,
U[i][k] * sqrt(S[k][k]) }
Görüldüğü üzere S matrisindeki köşegen değerleri (S[n][n] gibi) U matrisindeki i. satırdaki değerler ile çarpılmıştır.
Burada sqrt fonksiyonu karekök belirtir ve bir matrisin karakökü ile kastedilen aslında matrisin elemanlarının teker teker karekökünün alınmış halidir. S matrisi diyagonal bir matris olduğu için bu elemanların kareköklerinin alınması yeterlidir.
Yukarıdaki son denklemi bulduktan sonra koda geçirmek için yapılması gereken yukarıdaki matrisi hesaplayan bir döngü yazmaktır.
SVD Dosyası nedir?
SVD Sorunlarını Anlama
Tipik SVD Açılış Zorlukları
Polytec PSV Software Yüklü Değil
SVD dosyanıza çift tıklandığında “%%os%% SVD Dosyasını Açamıyor” mesajı istenir. Özel olarak, bu, Polytec PSV Software'in %%os%%'de yüklü olmadığı anlamına gelir. Bu, işletim sistemi dosyanın nasıl işleneceğini bilmediğinden SVD dosyasını açmak için çift tıklatmanızı engeller.
İpucu: SVD'nizi açacağını bildiğiniz başka bir program yüklediğinizde, listelenen diğer programlardan seçebilirsiniz (bkz. “Uygulamaları Göster”).
Polytec PSV Software Güncelleme Gerektiriyor
Bazı durumlarda, yüklü uygulama sürümünüz tarafından desteklenmeyen bir Scanning Vibrometer Data File dosyasının daha yeni (veya daha eski) bir sürümüolabilir. Polytec PSV Software'in en son sürümünü Polytec üzerinden yüklemek önerilir. Çoğu zaman, Scanning Vibrometer Data File dosyanızın yüklediğinizden daha yeni bir Polytec PSV Software tarafından oluşturulmuştur.
İpucu: Hangi sürüme ihtiyacınız olduğuna dair ipuçlarını bulmak için sağ tıklayıp “Özellikler” i seçerek SVD dosyanızı araştırın.
Özet: Her iki durumda da, SVD dosyasını açma sorunlarının çoğu bilgisayarınızda yüklü doğru yazılım uygulamasının bulunmamasından kaynaklanmaktadır.
SVD'leri Açma Sorunlarının Diğer Nedenleri
Scanning Vibrometer Data File dosyalarını açarken hatalar, bilgisayarınızda yüklü olan en son Polytec PSV Software yazılımı olsa bile ortaya çıkabilir. %%os%% içinde SVD'leri açarken bu hatalara neden olan dış sorunlar olabilir. Diğer katkıda bulunan nedenler:
- Windows Kayıt Defteri'ndeki SVD dosyası başvuruları bozuk
- Windows kayıt defterindeki SVD dosyasının açıklaması yanlışlıkla silmek
- Polytec PSV Software gibi bir SVD programının hatalı yüklenmesi
- SVD'nizin dosya bozulmasına neden olan bir şey
- SVD'niz kötü amaçlı yazılımlardan olumsuz etkilendi
- SVD'lerle ilgili donanım, aygıt sürücüsü bozulmasına neden olur
- Scanning Vibrometer Data File dosyalarını başarıyla açmak için yetersiz sistem kaynağı
Test: Bunlardan hangisi bir vektör görüntü dosyası olarak kabul edilir?

Doğru!
Böyle AI ve EPS gibi vektörel dosyalar hakkında benzersiz şey grafik ayrıntılar (örn. boyut ve şekillerde nesnelerin) ve metin düzenlenebilir kalmasıdır. Bu kaydedebilir ve Illustrator bunları yeniden açıp düzenlemelerine izin metin veya grafik içinde diğer unsurlar.
Yakın ama tam olarak değil...
Böyle AI ve EPS gibi vektörel dosyalar hakkında benzersiz şey grafik ayrıntılar (örn. boyut ve şekillerde nesnelerin) ve metin düzenlenebilir kalmasıdır. Bu kaydedebilir ve Illustrator bunları yeniden açıp düzenlemelerine izin metin veya grafik içinde diğer unsurlar.

İnme için Genetik Risk Faktörü
Özellikle 65 yaşından büyük hastalarda, yaygın bir genetik varyantın inme için bir risk faktörü olarak tanımlandığını gösteren çalışma
Şimdi Dinle
1240 Görüntülenme
02.17 Dakika
21 Nisan 2021

Geisinger araştırmacılarından oluşan bir ekip, özellikle 65 yaşından büyük hastalarda, yaygın bir genetik varyantı inme için bir risk faktörü olarak tanımladıklarını bildirmişlerdir. Yapılan çalışmalar serebral küçük damar hastalığının (SVD), dünya çapında inmelerin yaklaşık dörtte birine neden olmakla birlikte vasküler demansın en yaygın nedeni olduğunu göstermiştir. SVD, beyinde tipik olarak beyin taraması görüntülerinde görülen lezyonlar olarak ortaya çıkabilmektedir. Bilim insanları, SVD’nin genellikle yaşlanma ve hipertansiyon ile ilişkili olmasına karşın çok az vakaya NOTCH3 genindeki sistein değiştiren varyantların neden olduğunu belirtmişlerdir. Yaklaşık 300 kişiden 1'inde bu tip gen varyantı bulunmaktadır. Subkortikal enfarkt ve lökoensefalopatili serebral otozomal dominant arteriopati olarak bilinen nadir bir kalıtsal durum veya bu gen varyantının neden olduğu CADASIL, SVD ve artmış inme riski ile ilişkilendirilmiştir. Stroke'da yayınlanan çalışmalarında araştırmacılar, 118'i NOTCH3 varyantı sergileyen 300'den fazla Geisinger hastasının görüntüleme ve genomik sıralama verileri dahil olmak üzere bir dizi sağlık kaydını değerlendirmişlerdir. Bu grubun %12.6'sında inme öyküsü varken, kontrol grubundakilerinin %4.9'unda olduğu bildirilmiştir. 65 yaşından büyüklerde inme riski önemli ölçüde daha yüksek olmakla birlikte hastalar beyinde daha fazla sayıda beyaz madde lezyonu sergilemişlerdir.
NOTCH3 varyantlarının yüksek popülasyon sıklığı
Çalışma grubundaki 118 hastanın hepsinde NOTCH3 genetik varyantı olmasına rağmen, CADASIL'e neden olan spesifik varyant nadiren görülmüştür. Araştırma ekibi, NOTCH3 varyantlarının yüksek popülasyon sıklığı göz önüne alındığında, NOTCH3 varyantının bir sonucu olarak daha yüksek SVD ve felç riski altında olabilecek bireylerin sayısının önemli olduğunu belirtmişlerdir. Çalışma, NOTCH3 varyantına sahip çoğu kişinin 65 yaşından sonra NOTCH3 ile ilişkili SVD geliştireceğini göstermiştir. Geisinger'de moleküler ve fonksiyonel genomik bölümünde bir bilim insanı ve çalışmanın ortak yazarı olan Vida Abedi, inmenin, karmaşık çok faktörlü bir durum olduğunu belirtmiş ve risk faktörlerini incelemek ve hasta sonuçlarını iyileştirmenin yollarını belirlemenin, hasta bakımını iyileştirmenin çok önemli bir parçası olduğuna dikkat çekmiştir. Geisinger'de vasküler nörolog ve klinisyen-bilim insanı ve çalışmanın ortak yazarı olan Ramin Zand, bu çalışmanın, nörolojik hastalıkların genetik temelini incelemeye yönelik yeni ve güçlü bir yaklaşımı temsil ettiğini ifade etmiştir. Ayrıca Zand, Geisinger'in benzersiz kaynaklarının, elektronik sağlık kayıtları ve hassas tıbba odaklanmasının, tüm hastalarına daha iyi bakım sağlamak için bu verilerden yararlanmalarını sağladığını sözlerine eklemiştir.